LLM Implementations
ChatGPT and its competitors
Google has no moat is a supposedly-leaked internal Google memo that explains why open source versions of GPT language models will win. (via HN)
see counter-argument from Vu Ha
Is the 41% quality gap “slight”? IMO, it’s not. Our experiences have shown that a 50-to-60 improvement is significantly easier than a 80-to-90 improvement.
Benchmarking
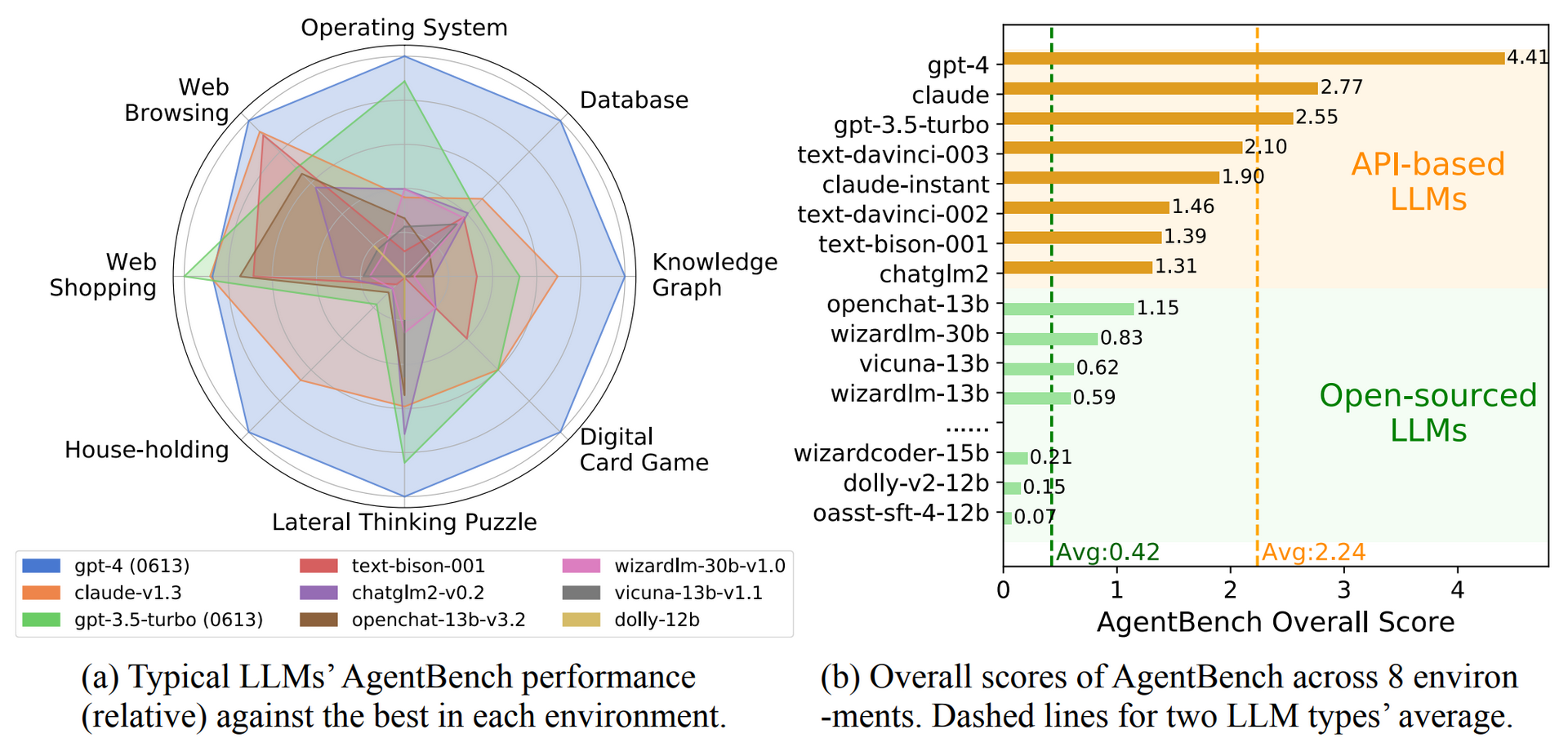
AgentBench is an academic attempt to benchmark all AI LLMs against each other.
Liu et al. (2023)
AgentBench, a multi-dimensional evolving benchmark that currently consists of 8 distinct environments to assess LLM-as-Agent’s reasoning and decision-making abilities in a multi-turn open-ended generation setting. Our extensive test over 25 LLMs (including APIs and open-sourced models)
The result: OpenAI’s GPT-4 achieved the highest overall score of 4.41 and was ahead in almost all disciplines. Only in the web shopping task, GPT-3.5 came out on top.
The Claude model from competitor Anthropic follows closely with an overall score of 2.77, ahead of OpenAI’s free GPT-3.5 Turbo model. The average score of the commercial models is 2.24.
see ($ The Decoder)
And Chris Coulson rates Azure vs OpenAI API speeds to show that Azure is approximately 8x faster with GPT-3.5-Turbo and 3x faster with GPT-4 than OpenAI.
For the most part you don’t have to worry about price differences between Azure and OpenAI, as the price is the same for all of their standard features. Prices are also quite affordable, especially GPT-3.5-Turbo, as running several rounds of testing only cost me a few cents.
Nicholas Carlini has a benchmark for large language models (GitHub) that includes a simple domain-specific language that makes it easy to add to the current 100+ tests. Most of these benchmarks evaluate the LLM for its coding capabilities.
- GPT-4: 49% passed
- GPT-3.5: 30% passed
- Claude 2.1: 31% passed
- Claude Instant 1.2: 23% passed
- Mistral Medium: 25% passed
- Mistral Small 21% passed
- Gemini Pro: 21% passed
A complete evaluation grid is available here.
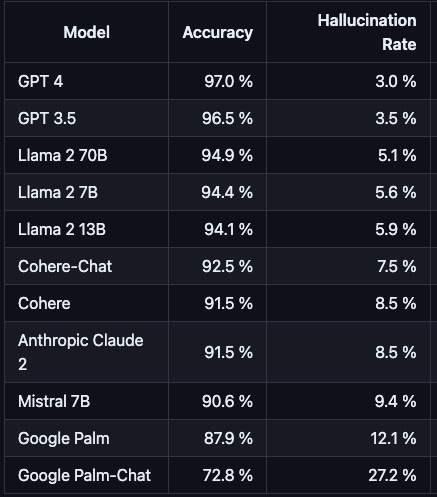
Hallucination
AI Hallucination Rate @bindureddy
OpenAI
OpenAI History and Principles for summaries of the company and its models, including leaked details of GPT-4
Evaluating GPT-4:
Coagulopath started the discussion but no longer thinks it’s gotten worse. Using example queries about Italian history and rock music, he shows there’s much nuance in how to interpret the accuracy of an answer and it’s impossible to say whether the later models are better or worse.
in Is GPT-4 getting worse over time? AI Snake Oil argues that no, GPT-4 is not getting worse like some studies have claimed. Good discussion of how you would dissect an LLM.
Amazon Olympus
The training data for the secretive project is reportedly vast. The model will have a whopping 2 trillion parameters, which are the variables that determine the output of a given model, making it one of the largest currently in development. In comparison, OpenAI’s GPT-4 LLM has “just” one trillion parameters, according to Reuters.
Claude
Anthropic @AnthropicAI
see AI Safety Issues
also see Perplexity Copilot, which uses the Claude (and other?) API to give better answers.
LLama
It was trained on 2T tokens and they have models up to 70B parameters. The paper linked in the blog has rich details and impressive tidbits that the community has guessed at but never confirmed, primary of which is around the absolute foundational nature of training the reward model properly. It’s harder to get right than it seems.
Meta’s Llama model used 2,048 Nvidia A100 GPUs to train on 1.4 trillion tokens, a numerical representation of words, and took about 21 days, according to a CNBC report in March. (SCMP)
Nathan Lambert writes a Llama 2: an incredible open LLM on how Meta is continuing to deliver high-quality research artifacts and not backing down from pressure against open source.
While doubling the training corpus certainly helped, folks at Meta claim the reward model and RLHF process was key to getting a safe and useful model for Llama 2’s release. If you didn’t have time to read the full technical paper, this post is an excellent summary of key ideas from the head of RLHF at HuggingFace.
A blog post at Cursor.so makes the case for Why GPT-3.5 is (mostly) cheaper than Llama 2
Instructions for How to Run Llama-2 locally. The smallest model runs in 5-6G RAM and is 2-3GB of disk space.
Superfast AI Newsletter Alexandra Barr writes a detailed description of LLama: “Llama 2 Explained: Training, Performance and Results
Diving into Meta’s Llama 2 model and how it compares to SOTA open- and closed-source LLMs.”
Brian Kitano shows Llama from scratch (or how to implement a paper without crying): implements TinyShakespeare, essentially a chatbot trained on Shakespeare corpus using the same techniques as Llama did on its huge corpus.
Cameron Wolfe does a incredibly deep-dive
Dolma (AI2)
Dolma stands for “Data to feed OLMo’s Appetite”
AI2 Dolma: 3 Trillion Token Open Corpus for Language Model Pretraining

Our dataset is derived from 24 Common Crawl snapshots collected between 2020–05 to 2023–06. We use the CCNet pipeline to obtain the main content of each web page in plain text form. Further, we also use the C4 dataset, which is obtained from a Common Crawl snapshot collected in April 2019.
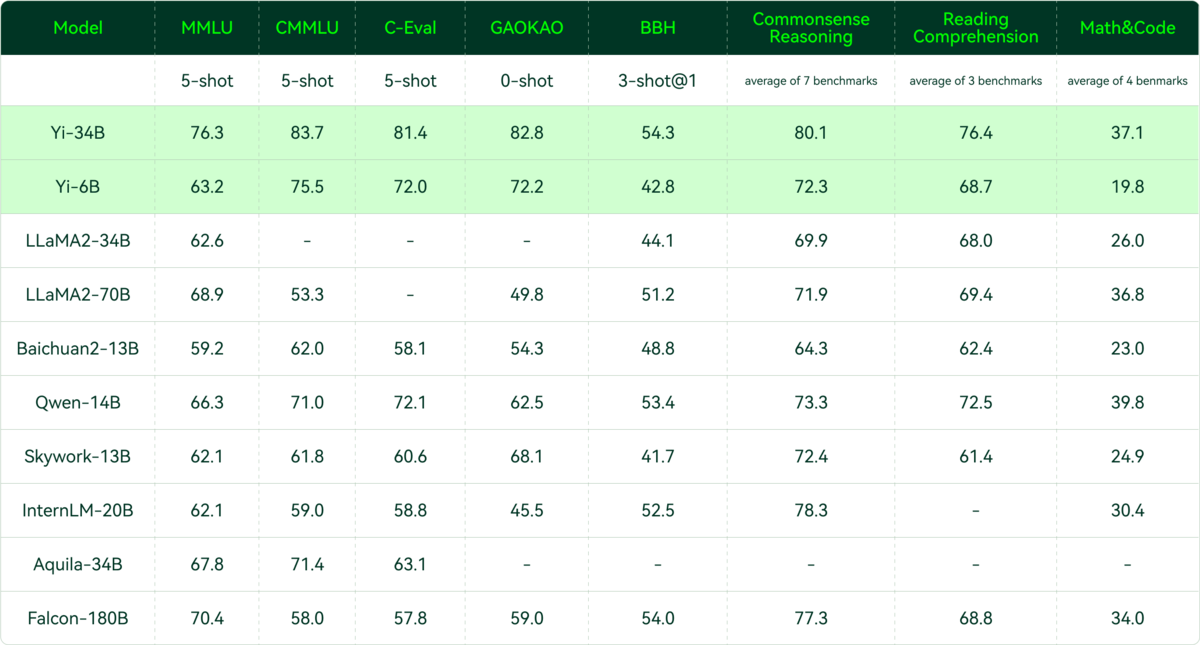
01.AI: (China)
See Hacker News discussion
X.AI (Grok)
Grok, released to Premium X users on Nov 5, 2023, has these goals
Gather feedback and ensure we are building AI tools that maximally benefit all of humanity. We believe that it is important to design AI tools that are useful to people of all backgrounds and political views. We also want empower our users with our AI tools, subject to the law. Our goal with Grok is to explore and demonstrate this approach in public.
Empower research and innovation: We want Grok to serve as a powerful research assistant for anyone, helping them to quickly access relevant information, process data, and come up with new ideas.
trained a prototype LLM (Grok-0) with 33 billion parameters. This early model approaches LLaMA 2 (70B) capabilities on standard LM benchmarks but uses only half of its training resources. In the last two months, we have made significant improvements in reasoning and coding capabilities leading up to Grok-1, a state-of-the-art language model that is significantly more powerful, achieving 63.2% on the HumanEval coding task and 73% on MMLU.
IBM (MoLM)
Open source Mixture of Experts “MoLM is a collection of ModuleFormer-based language models ranging in scale from 4 billion to 8 billion parameters.”
Mistral (France)
https://mistral.ai/ (via The Generalist) Founded by Guillaume Lample, Arthur Mensch, and Timothe Lacroix to build an ecosystem hinged on first-class open-source models. This ecosystem will be a launchpad for projects, teams, and eventually companies, quickening the pace of innovation and creative usage of LLMs.
Mistral-7B-v0.1 is a small, yet powerful model adaptable to many use-cases. Mistral 7B is better than Llama 2 13B on all benchmarks, has natural coding abilities, and 8k sequence length. It’s released under Apache 2.0 licence. We made it easy to deploy on any cloud, and of course on your gaming GPU
Try it out on HuggingFace Model Card for Mistral-7B-Instruct-v0.1
Perplexity
Attempting to become your premiere search destination, the company released its own AI large language models (LLMs) — pplx-7b-online and pplx-70b-online, named for their parameter sizes, 7 billion and 70 billion respectively. They are fine-tuned and augmented versions of the open source mistral-7b and llama2-70b models from Mistral and Meta.
see VentureBeat’s good summary.

Tongyi Qianwen (Alibaba)
Tongyi Qianwen allows AI content generation in English and Chinese and has different model sizes, including seven billion parameters and above.
Alibaba will be open-sourcing the seven-billion-parameter model called Qwen-7B, and a version designed for conversational apps, called Qwen-7B-Chat
Open source Qwen-VL and Qwen-VL-Chat can understand images and carry out more complex conversations.
ERNIE (Baidu)
A professional plan that gives users access to Ernie Bot 4.0 for 59.9 yuan (US$8.18) per month
 文心一言
文心一言
有用、有趣、有温度
iFlytek (China)
Company says iFlytek Spark 3.0, first unveiled by the company in May, has outperformed GPT-3.5 in six abilities
Open Source
Varun: “Why Open Source will win”: lengthy, detailed argument why LLMs are like Linux and have a fundamental long-term advantage over closed source.
Open source models are smaller and run on your own dedicated instance, leading to lower end-to-end latencies. You can improve throughput by batching queries and using inference servers like vLLM.
There are many more tricks (see: speculative sampling, concurrent model execution, KV caching) that you can apply to improve on the axes of latency and throughput. The latency you see on the OpenAI endpoint is the best you can do with closed models, rendering it useless for many latency-sensitive products and too costly for large consumer products.
On top of all this, you can also fine-tune or train your own LoRAs on top of open source models with maximal control. Frameworks like Axolotl and TRL have made this process simple5. While closed source model providers also have their own fine-tuning endpoints, you wouldn’t get the same level of control or visibility than if you did it yourself.
Technology Innovation Institute and startups MosaicML and Together are pushing forward their own open-source AI software.
Bing Chat
Gwern speculates about Microsoft’s Sydney
Other
DarkBERT: A Language Model for the Dark Side of the Internet: a language model pretrained on Dark Web data, shows promise in its applicability on future research in the Dark Web domain and in the cyber threat industry.
Jin et al. (2023)